Leading AI systems designs are migrating away from building the fastest AI processor possible, adopting a more balanced approach that involves highly specialized, heterogeneous compute elements, faster data movement, and significantly lower power.
Part of this shift revolves around the adoption of chiplets in 2.5D/3.5D packages, which enable greater customization for different workloads and data types, and better performance per watt. Alongside of that, leading-edge chipmakers used the recent Hot Chips 24 conference to show off novel micro-architectures, improvements in pre-fetch and branch prediction, faster memory access, and more intelligent data management on and off chip.
These new designs also take aim at NVIDIA’s near monopoly in the AI world due to the proliferation of inexpensive GPUs and the CUDA-based models built atop of them. No general-purpose processor is as energy-efficient as customized accelerators, and rather than a single type of chip, most of the multi-chiplet architectures presented at Hot Chips this year include more than one type of processor, more expansive memory and I/O configurations to limit bottlenecks, and much more efficient data management.
NVIDIA is well-aware of these competitive threats, of course, and the company certainly is not standing still. Its new Blackwell chip combines GPUs with a CPU and DPU, and its quantization scheme opens the door to low-precision AI in addition to its blazing fast training capabilities, which are needed to handle much larger data models.
NVIDIA still has plenty of expansion opportunities ahead, but going forward it will face more competition on many fronts.
 |
| AI models have grown by a factor of 70,000 over a decade as new capabilities and parameters are added. Source: NVIDIA/Hot Chips 24 |
Changes in the data center
One of the big changes in processor designs this year is an intensive focus on data management. With AI, it’s no longer just about building massive arrays of redundant processing elements and running them as fast as possible. Increasingly, the goal is to intelligently prioritize data — there is much more data, and more types of data — but this approach isn’t new. In fact, it dates back to 1980, when Intel introduced its 8087 floating point co-processor. Arm expanded on that concept in 2011 with its big.LITTLE dual-core processor, with the smaller core targeted at less compute-intense jobs and the larger core there when needed.
Even IBM, which claims to handle 70% of all the financial transactions in the world through its mainframe computers, has shifted direction away from focusing just on tera operations per second (TOPS) to performance per watt (aka picojoules per second). This is especially noteworthy because, unlike large systems companies — which now account for an estimated 45% of all leading-edge chip designs — IBM sells its systems to end customers rather than just compute as a service.
IBM’s new Telum processor includes a mix of a data processing unit (DPU) for I/O acceleration — basically, funneling data to where it will be processed and stored — as well as innovative caching. In all, it contains 8 cores running at 5.5 GHz, 10 36-megabyte L2 caches, and a new accelerator chiplet.
“DPUs are being widely used in the industry for handling massive amounts of data very efficiently,” said Chris Berry, IBM distinguished engineer. “Mainframes handle massive amounts of data. One fully configured IBM z16 is able to process 25 billion encrypted transactions each and every day. That’s more encrypted transactions per day than Google searches, Facebook posts, and Tweets combined. That kind of scale requires I/O capabilities well beyond what typical compute systems can deliver. It requires custom I/O protocols to minimize latency, support virtualization for thousands of operating system instances, and can handle tens of thousands of I/O requests at any time.”
The new chip also features a 15% power reduction in the eight-core central compute complex, in part due to better branch prediction. That has been a consistent theme at Hot Chips conferences over the past couple years, where more accurate branch prediction and faster recovery from pre-fetch errors can improve performance. But the addition of a DPU takes that a step further, acting as a smart traffic cop for data. Berry noted the DPU is mounted directly on the processor chip, and can reduce the amount of power needed for I/O management by 70%. Add to that a 2MB scratchpad for each of the 32 cores in its accelerator chip, which he described as “simply a place to put data for later use,” and the improvements in performance per watt are noteworthy.
 |
| IBM’s new Spyre accelerator architecture. Source IBM/Hot Chips 24 |
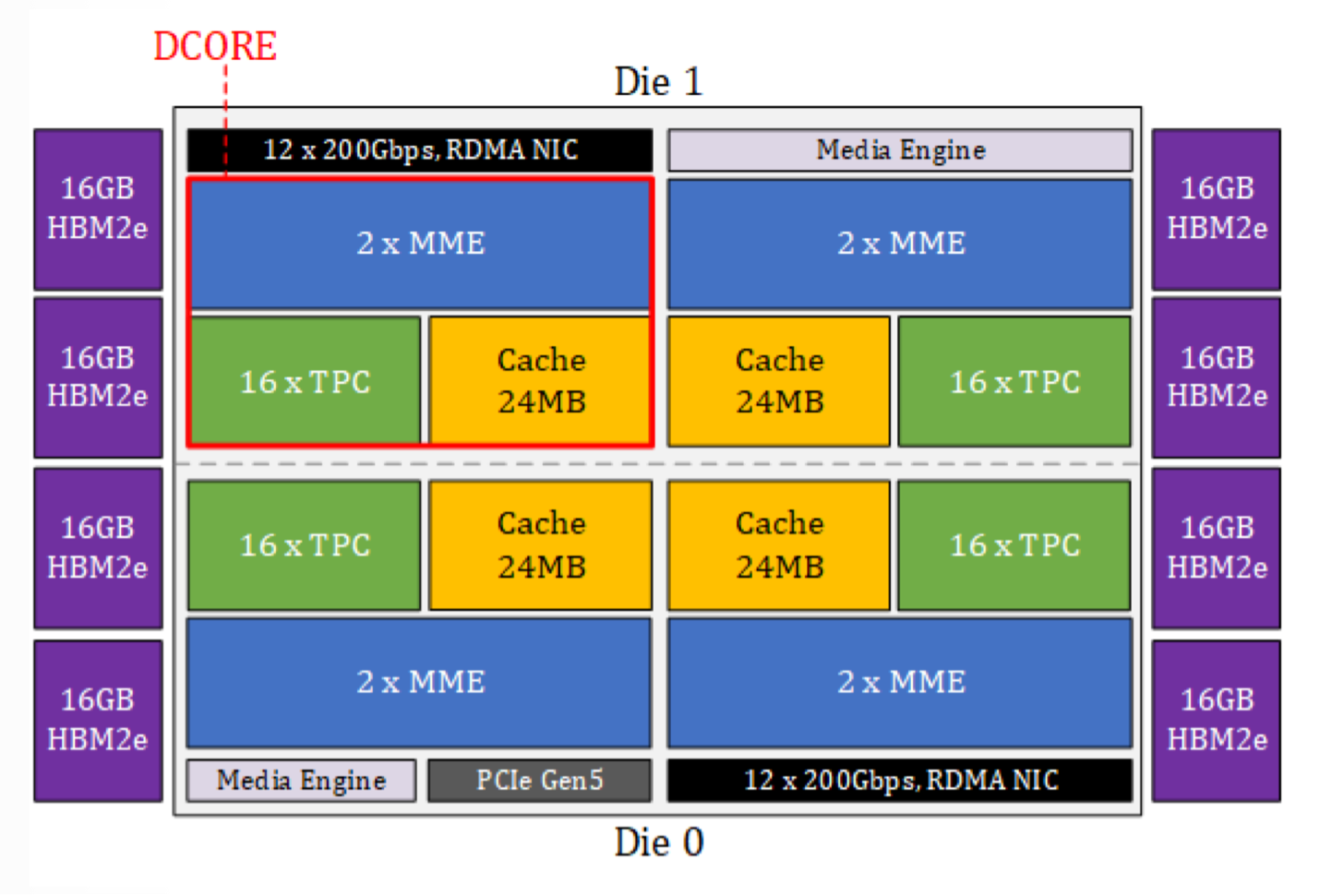
Intel likewise introduced its next-gen accelerator chip for AI training, the Gaudi 3, which features 4 deep learning cores (DCOREs), 8 HBM2e stacks, a matrix multiplication engine that is configurable as opposed to programmable. Add to that 64 tensor processing cores, and a memory sub-system that includes a unified memory space of L2 and L3 cache and HBM, near-memory compute, and an integrated software suite that allows customers to plug in custom TPC kernels, as well as support for PyTorch. It also connects two compute dies over an interposer bridge.
Intel’s approach to data management within the device is similar in concept to IBM’s. Intel uses a Sync Manager to dispatch work to designated units, and a Runtime Driver that sets work dependencies by configuring the Sync Manager. This approach maximizes resource utilization within the system, and it avoids any bottlenecks by asynchronously passing events using an interrupt manager.
“Each of the deep learning cores contains 2 MMEs (matrix multiplication engines), 16 tensor processing cores, and 24 megabytes of cache,” said Roman Kaplan, principal AI performance architect at Intel. “The main workhorse of the chip is the MME. It does all the operations that can be translated to matrix multiplication. This is a configurable — not a programmable —engine, meaning you don’t have any piece of code that’s running on this engine. There is a fixed set of registers that controls the operation of this unit, and according to these values, the unit just works. Each MME unit is basically a large output stationary systolic array.”
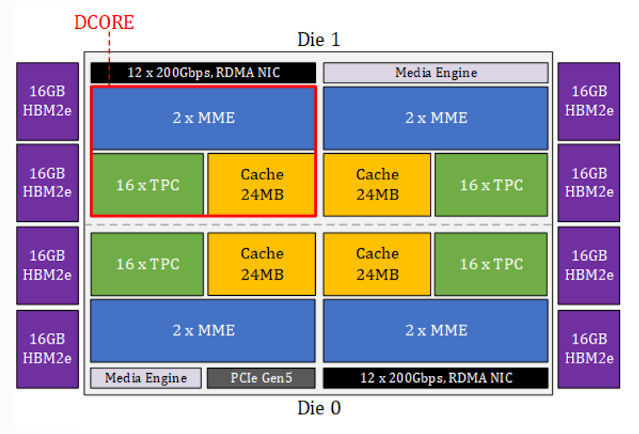 |
| Block diagram of Intel’s Gaudi 3 AI. Source: Intel/Hot Chips 24 |
AMD’s MI300X chip, which is aimed at AI systems, is based on a distributed AI system comprised of 12 chiplets, with 4 I/O dies and 8 accelerator dies, and likewise funnels data to where it is best processed. “Generative AI model performance requires memory capacity and bandwidth,” said Alan Smith, senior fellow and Instinct lead SoC architect at AMD. “So we targeted the scale of MI300X to meet this need, with a level of integration not possible with a monolithic design. Its fourth-generation Infinity fabric, PCI Express Gen 5, HBM3, and CDMA3 architecture, MI300X provides balanced scaling across compute, memory, and I/O subsystems.”
 |
| AMD’s MI300X chiplet-based AI chip. Source: AMD/Hot Chips 24 |
Qualcomm, meanwhile, developed its custom Oryon SoC along the same general lines. It includes three CPU clusters, each with four cores. Two of those are geared toward performance and one toward energy efficiency. What stands out in many of these presentations is the micro-architecture, which is basically how instructions are executed on the hardware. As with much larger systems, how and where data is processed and stored is central to many of these designs.
“[Oryon] has 8 fundamental decoders in it, and they are preparing instructions for executions units, the load store unit, and the vector execution unit,” said Gerard Williams, senior vice president of engineering at Qualcomm. “The instructions themselves enter into a re-order buffer. It’s around 600 entries, which gives you an idea about how many instructions the machine is going to be managing in flight. And from a retirement point of view, there are 8 instructions per cycle this machine can retire.”
Of particular note in Qualcomm’s chip is the memory management unit. “It’s backed by a very large unified Level 2 translation buffer, and this is done primarily to handle a large data footprint,” Williams said. “It’s meant to handle all of the virtualized structures, the security layers, but this structure is much larger than 8 kilo-entries, which is very non-typical. It’s meant to keep the latency of translation down to an absolute minimum.”
 |
| Qualcomm’s Oryon SoC schematic, with dual emphasis on efficiency and speed. Source: Qualcomm/Hot Chips 24 |
Many of the presentations at the conference were from familiar names, but there were some newcomers, as well. Consider FuriosaAI, for example, a South Korea-based startup developing AI chips for the edge. The company developed what it calls a tensor contraction processor for sustainable AI computing.
“While training is all about AI models, inference is about services and deployment,” said June Paik, co-founder and CEO. “Our original design in 2021 was optimized for BERT-scale models. However, we soon made a major shift in our design with the emergence of foundation models such as GPT3 — a model five times larger than BERT. Even though those gigantic models were primarily in the research phase, we bet on their its potential. We believe people will gravitate toward the most capable AI models because more intelligent models offer greater benefits. We also believe that efficiency will become even more critical as we scale these applications. So we set out to make RNGD [pronounced Renegade] the most efficient inferencing chip.”
Moving data quickly back and forth to memory is central to its architecture, which is aimed at edge data centers. The company claims a memory bandwidth of 1.5 TB/second. RNGD also has two HBM3 stacks and 256 MB of SRAM, as well as a 48 GB memory capacity.
 |
| Furiosa’s sustainable edge inferencing chip architecture. Source: Furiosa/Hot Chips 24 |
So in conclusion AI is becoming increasingly useful, but challenges remain. Sustainability is crucial, as highlighted by chip architectures at Hot Chips 24. However, chips alone aren’t enough.
To achieve sustainability, we need more efficient software, enhanced micro-architectures to reduce the frequency of large language model queries, and improved precision in responses for greater trustworthiness. Additionally, integrating specialized processing elements like chiplets will enable faster and more efficient handling of diverse data types.
Credits:
@semiengineering.com
@Hot Chips 24








Comments
Post a Comment
For any correction, doubts or suggestion, please let me know